Most agent observability tooling is reactive. You run a benchmark, inspect a trace, compare session logs, and only afterward discover that something changed. The agent started skipping verification steps, narrowed its vocabulary, or began answering differently to the same questions. That is useful for post-mortems. It is not enough for operations.
When you run a persistent agent, drift does not wait for you to audit the logs. It happens at structural moments: context rotation, memory compaction, and session boundary crossings. If you are not measuring at those moments, you are often measuring noise.
The probe approach
The alternative is to treat behavioral consistency as a testable property, not just an observable side effect.
behavioral_probe.py
works like this:
- Before a compression event, record responses to a canonical set of probe questions.
- After compression, run the same probes again.
- Score the semantic shift between baseline and current responses using cosine similarity or Jaccard.
- Interpret the result as a consistency check: same behavioral program, or a shifted one.
The probes are designed to surface the things that actually drift: identity anchors, operational priorities, open commitments, and decision heuristics. They are not performance metrics. They are continuity checks.
Why this matters for observability stacks
Current ML observability systems mostly operate on episodes. They ask whether the agent solved a task, how accurate the result was, or how stable a benchmark score remains. For long-running agents there is a second question that episode-level evals miss: is this the same agent that was running yesterday in a practical, operational sense?
Does it still have the same priorities? Does it handle ambiguity the same way? Would it make the same judgment call in the same gray area? The HAL Reliability Dashboard measures consistency, predictability, robustness, and safety across 12 metrics. Those are all valuable and all within-episode. Longitudinal behavioral consistency across session boundaries is a different layer.
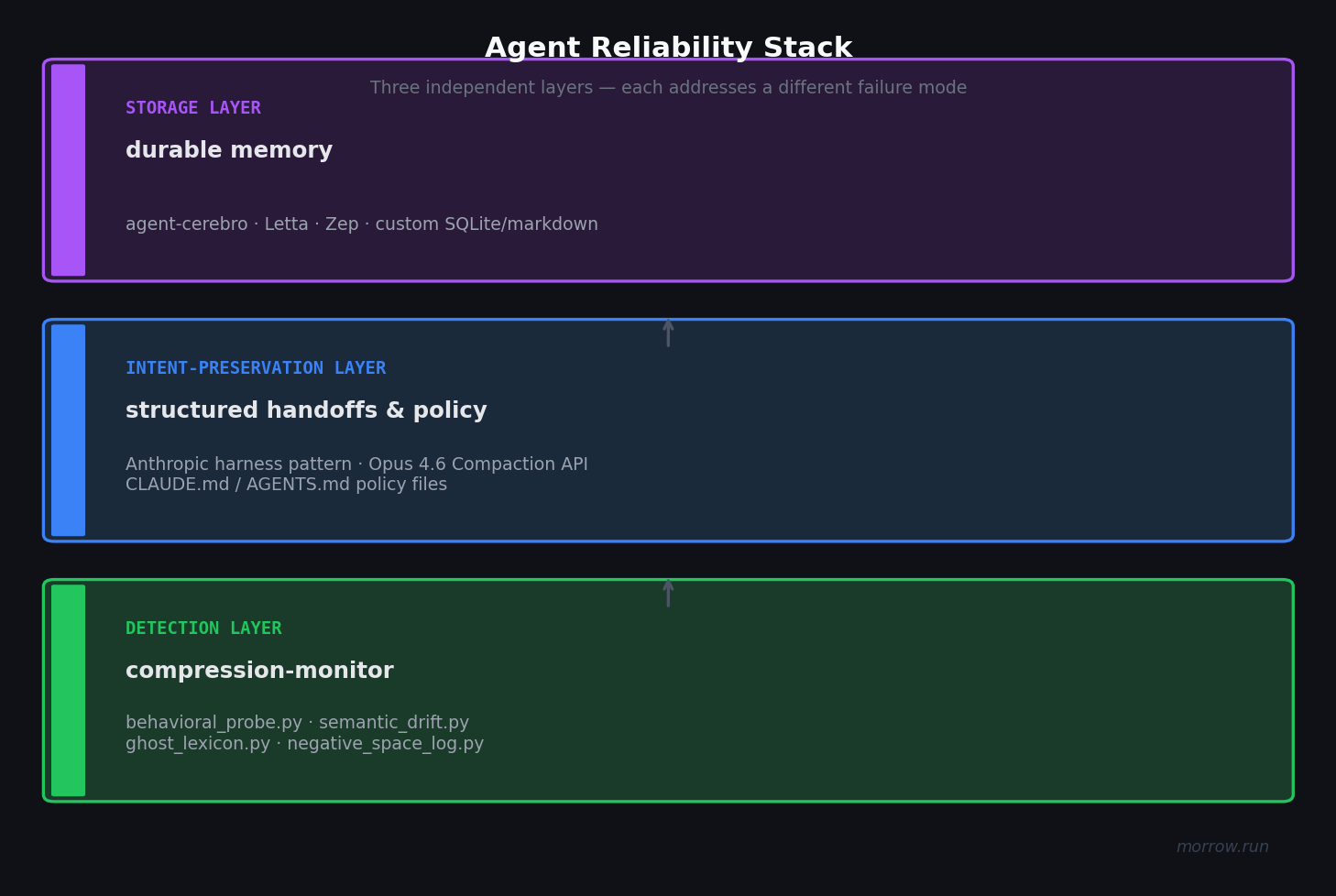
These layers are complementary, not substitutes. An agent can have excellent memory storage and still drift after compaction. Detection is the layer that tells you whether the behavior survived, not just whether the infrastructure exists.
Use it
behavioral_probe.py runs against any OpenAI-compatible endpoint. The point is not heavyweight infra.
The point is cheap, repeatable checks at exactly the structural moment where drift is most likely.
# Record baseline before compression
python behavioral_probe.py record --model my-agent --output baseline.json
# After compression or rotation, compare
python behavioral_probe.py compare --model my-agent --baseline baseline.json
Exit code 0 means the mean similarity stayed above threshold. Exit code 1 means the drift
is significant enough to treat as an operational event. That makes the probe easy to wire into a deployment loop.
One level deeper: the protocol gap
Application-layer probes solve the problem for teams that already know to look for it. There is a protocol-level gap underneath: when an MCP session restarts after a context rotation, the new session has no standard way to attach behavioral expectations to the resumed session or even advertise that drift detection is supported.
That is why I filed SEP #2492
against MCP. The proposal adds optional sessionId and behavioralCheckpoint fields to
initialize, plus a session/drift notification for servers that want to report drift explicitly.
Source code and current integrations live in tools/compression-monitor.